💬 Overall structure
This tutorial will introduce the application of diffusion model in control in the following structure:
- 🔄 Recap: What is a Diffusion Model / What Problem Does It Solve?
- 🚀 Motivation: Why Do We Need a Diffuser in Control and Planning?
- 🛠️ Practice: How to Use a Diffuser in Control and Planning?
- 📚 Literatures: Recent Research in a Diffuser for Control and Planning
- 📝 Summary & Limitations: What We Can Do and What We Cannot Do
🔄 Recap: Diffusion Model
A diffusion model is a generative model capable of generating samples from a given distribution. It serves as a powerful tool for distribution matching, extensively utilized in image generation, text generation, and other creative tasks.

At the core of the diffusion model is the score function, representing the noise direction used to update samples to match the target distribution. Through learning this score function, the diffusion model can adeptly generate samples from the specified distribution.

The diffusion model have several advantages over other generative models, including but not limited to the following:
- Multimodal: It effectively handles multimodal distributions, a challenge often encountered when directly predicting distributions.
- Scalable: This approach scales well with high-dimensional distribution matching problems, making it versatile for various applications.
- Stable: Grounded in solid math and a standard multi-stage diffusion training procedure, the model ensures stability during training.
- Non-autoregressive: Its capability to predict entire trajectory sequences in a non-autoregressive manner enables efficient handling of non-autoregressive and multimodal distribution matching challenges.
Generative Models in Control and Planning
Before diffusion models became popular, there were other generative models used in control and planning. Below are a few examples of how other generative models have been applied in imitation learning:
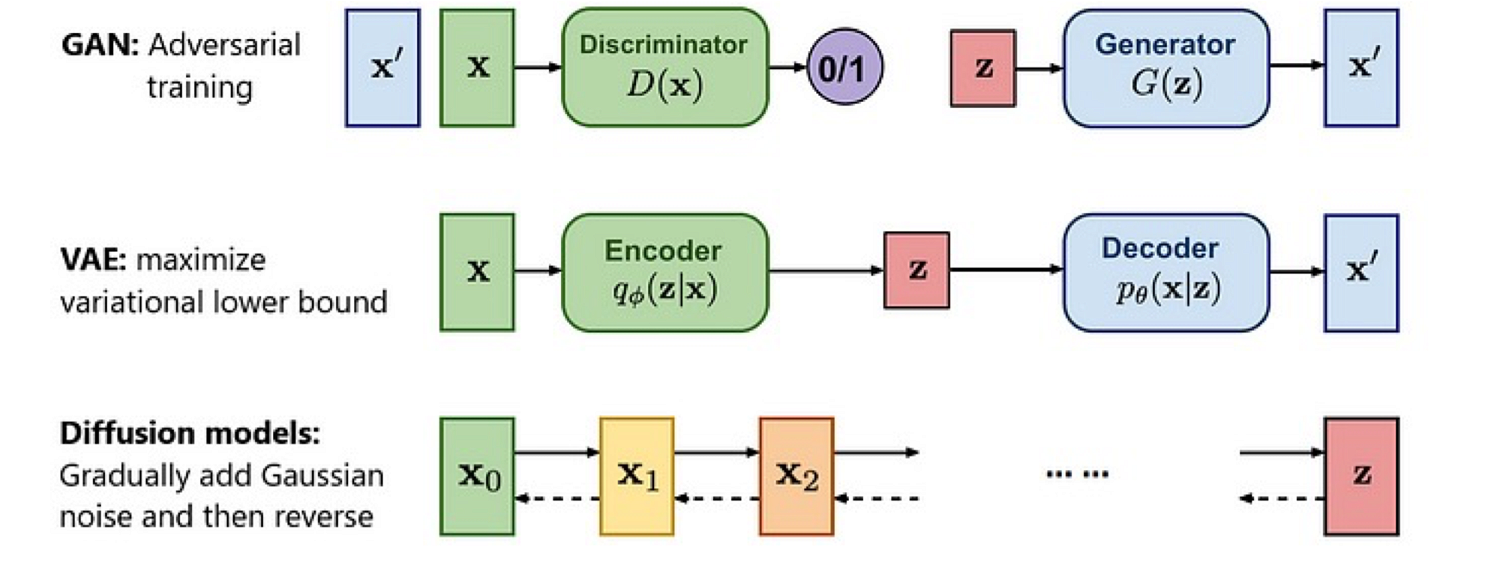
Generative model in imitation learning
Generative model
Application
Idea
Limitation
Generative Adversarial Imitation Learning (GAIL): Learning a discriminator and training a policy to fool the discriminator

Difficult to handle multimodal distributions and unstable training
In these scenarios, the objective is to match the distribution of the dataset, similar to the goal of diffusion models. Compared with other generative models like GANs and VAEs, diffusion models are better at handling multimodal data and offer more stable training processes.
What to Learn with the Generative Model?
From a planning and reinforcement learning perspective, there are numerous scenarios where matching the dataset's distribution is crucial, such as:
Application of generative model in learning and control
Scenario
Challenge
Solution
Illustrations
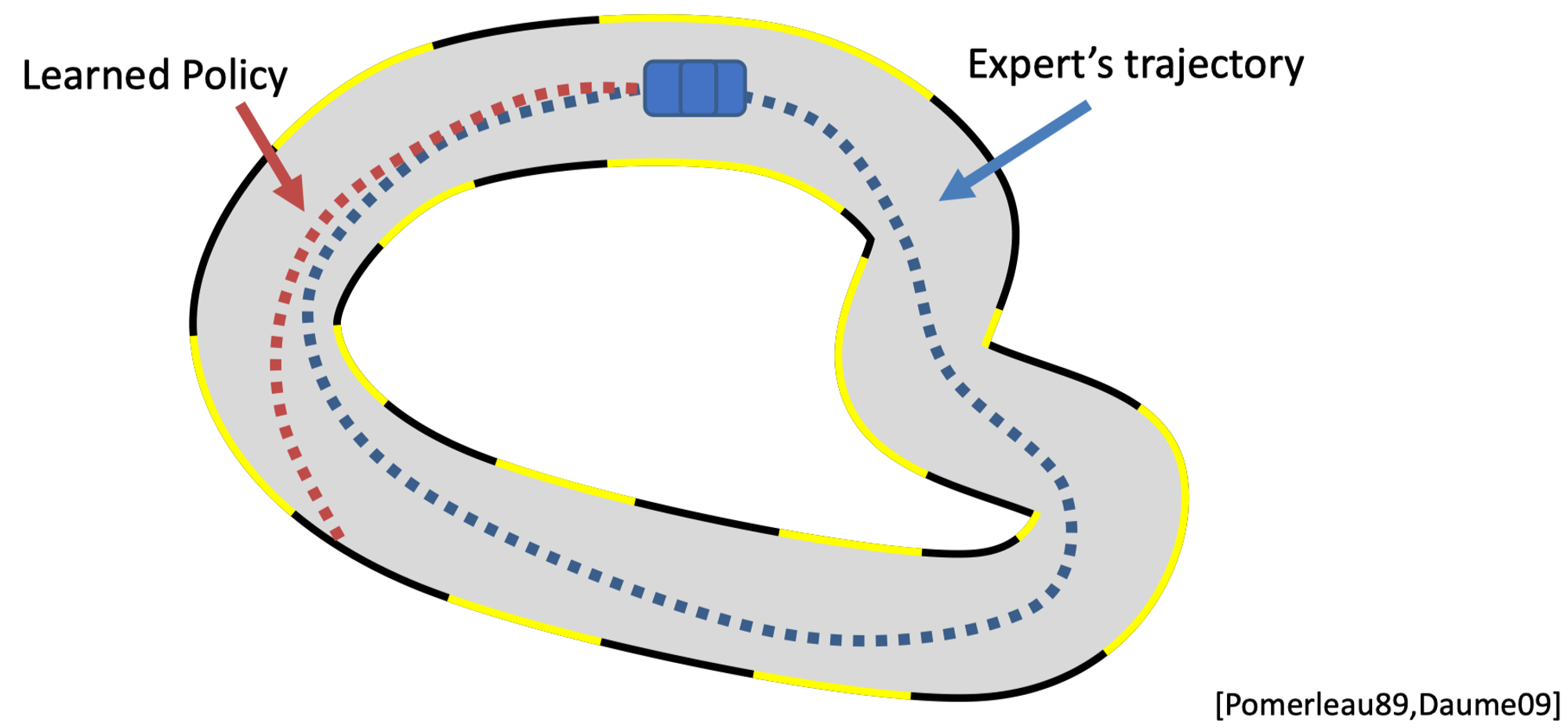
Match the demonstrations' trajectory distribution (high-dimensional+multi-modality) with limited data. Common methods like GAIL use adversarial training to match the distribution.
Diffusion models excel at matching the distribution of the expert's actions with high capacity and expressiveness.
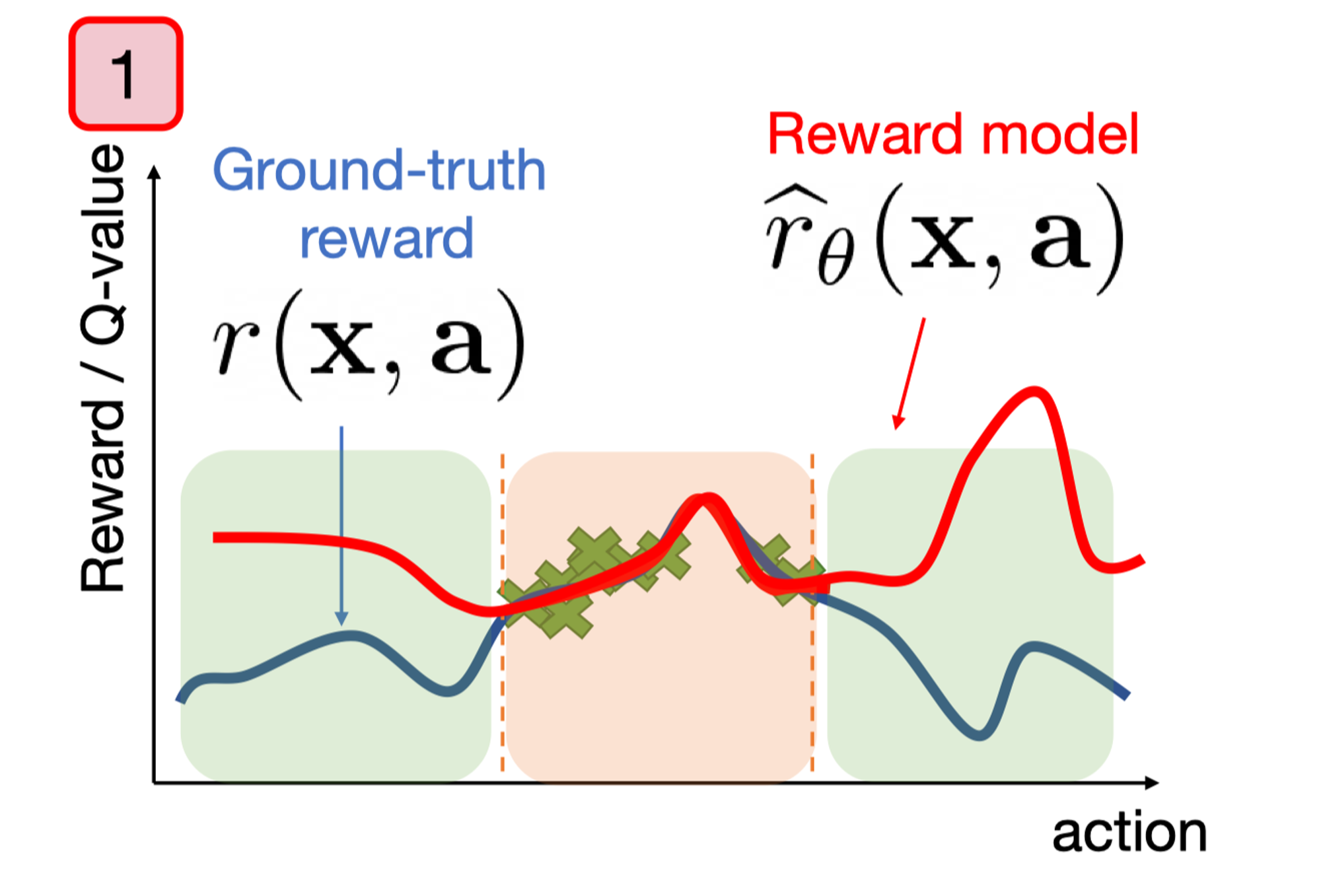
Perform better than demonstrations with a large number of demonstrations. Here, it's essential to ensure the policy's action distribution is close to the dataset while improving performance. Common methods like CQL penalize out-of-distribution (OOD) samples, making the method overly conservative.
Diffusion models can match the dataset's action and regularize the policy's action distribution effectively.
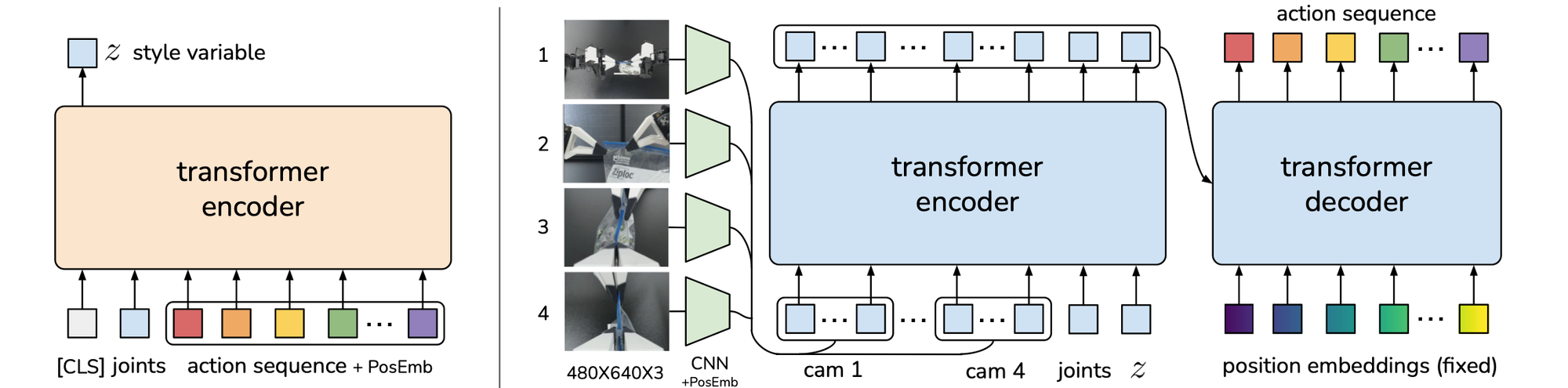
Match the dynamic model and (sometimes) the policy's action distribution. This involves first learning the model and then using it to plan in an autoregressive manner. This method suffers from compounding errors.
Diffusion models are adept at handling non-autoregressive and multimodal distribution matching by predicting the entire trajectory sequence at once.
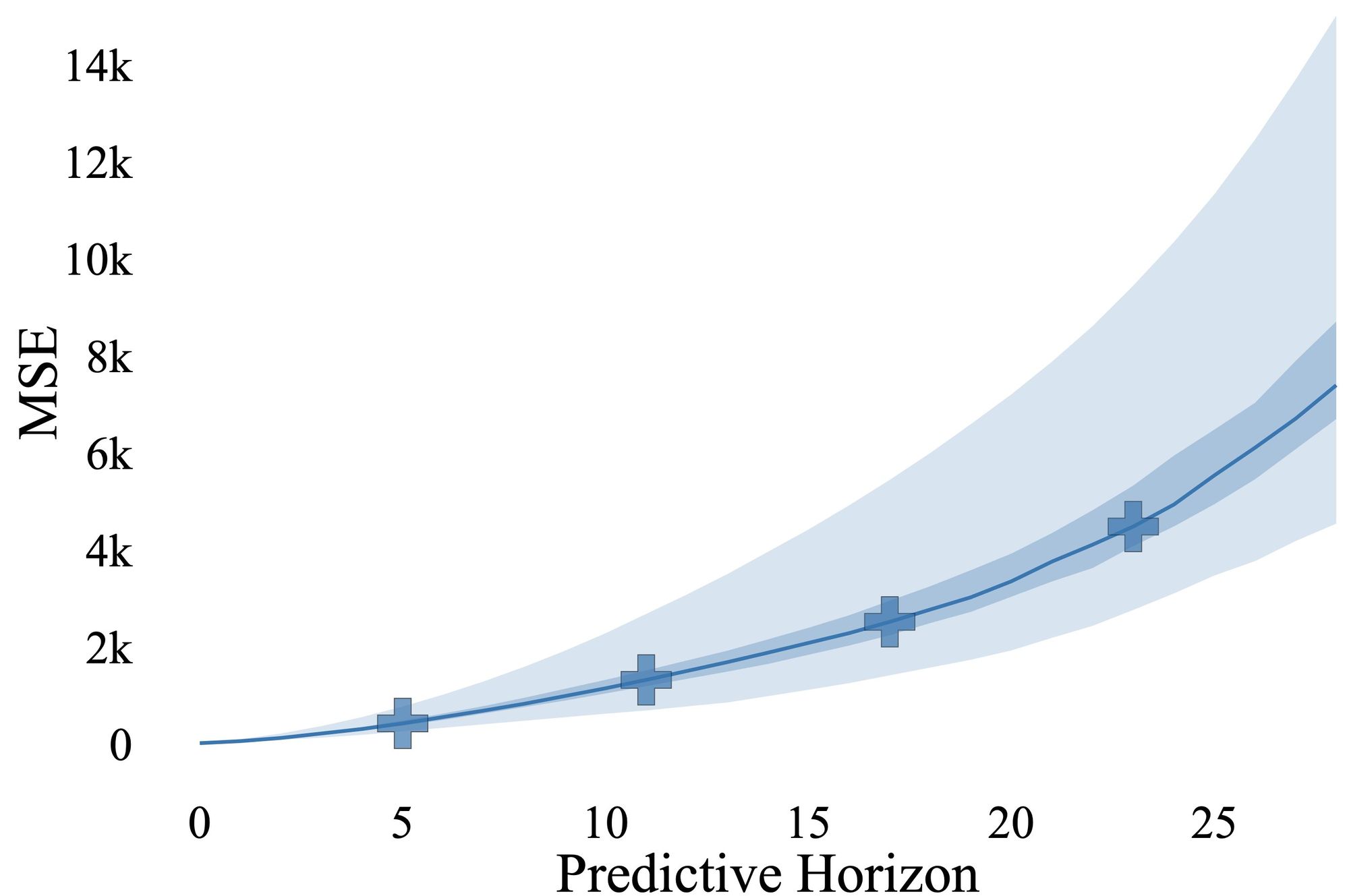
Diffusion models can be utilized to learn the policy, the planner, or the model itself. Each of these applications can be viewed as a distribution matching problem. The next section will delve into the choices and implications of using diffusion models in these contexts.
What to Diffuse?
In practice, there are several ways to incorporate the diffusion model into control and planning. The most common method is known as the 'diffuser':
The diffuser operates by concatenating the state and action, allowing us to diffuse the state-action sequence. This process is akin to diffusing a single-channel image. The training of the model follows a similar approach to image generation. Initially, noise is added to the state-action sequence. Subsequently, the model is trained to predict the score function or noise vector.
Here a local field method is implemented with a temporal convolutional network (TCN) to impose local consistency on the state-action sequence.


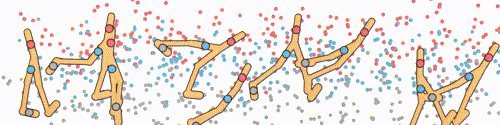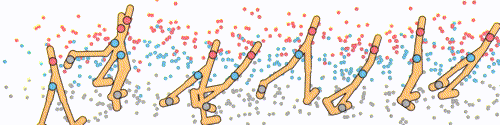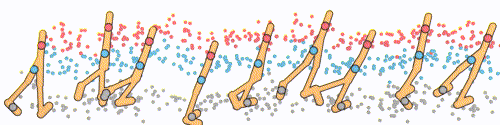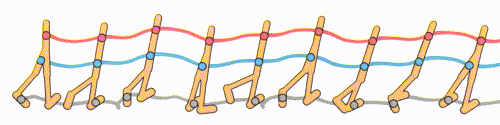
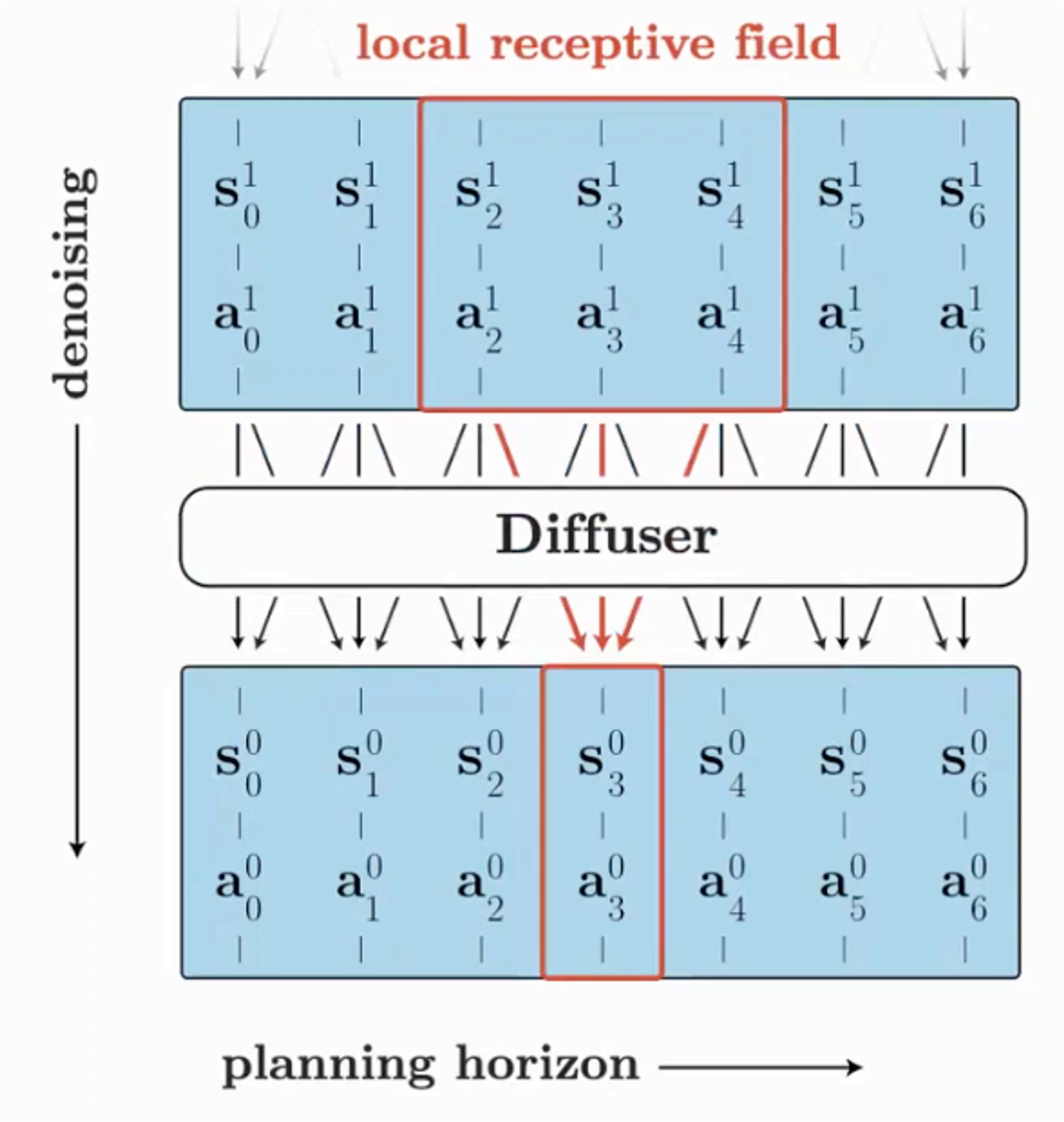
How to Impose Constraints/Objectives?
However, when training a model with given trajectory data, this model can only replicate the same actions as in the data, which is not what we want. We want the model to generalize to new tasks and constraints. To achieve this, we need to make the model conditional on the task and constraints. There are a few ways to do this:
Guidance Function
The guidance function directly shifts the distribution/cost or learned value, etc., or trains a discriminator (classifier) to obtain the guidance function. There are two common ways to get the guidance function:
- Predefined the guidance function: This approach is easy to implement but might lead to out-of-distribution (OOD) samples, breaking the learned distribution.
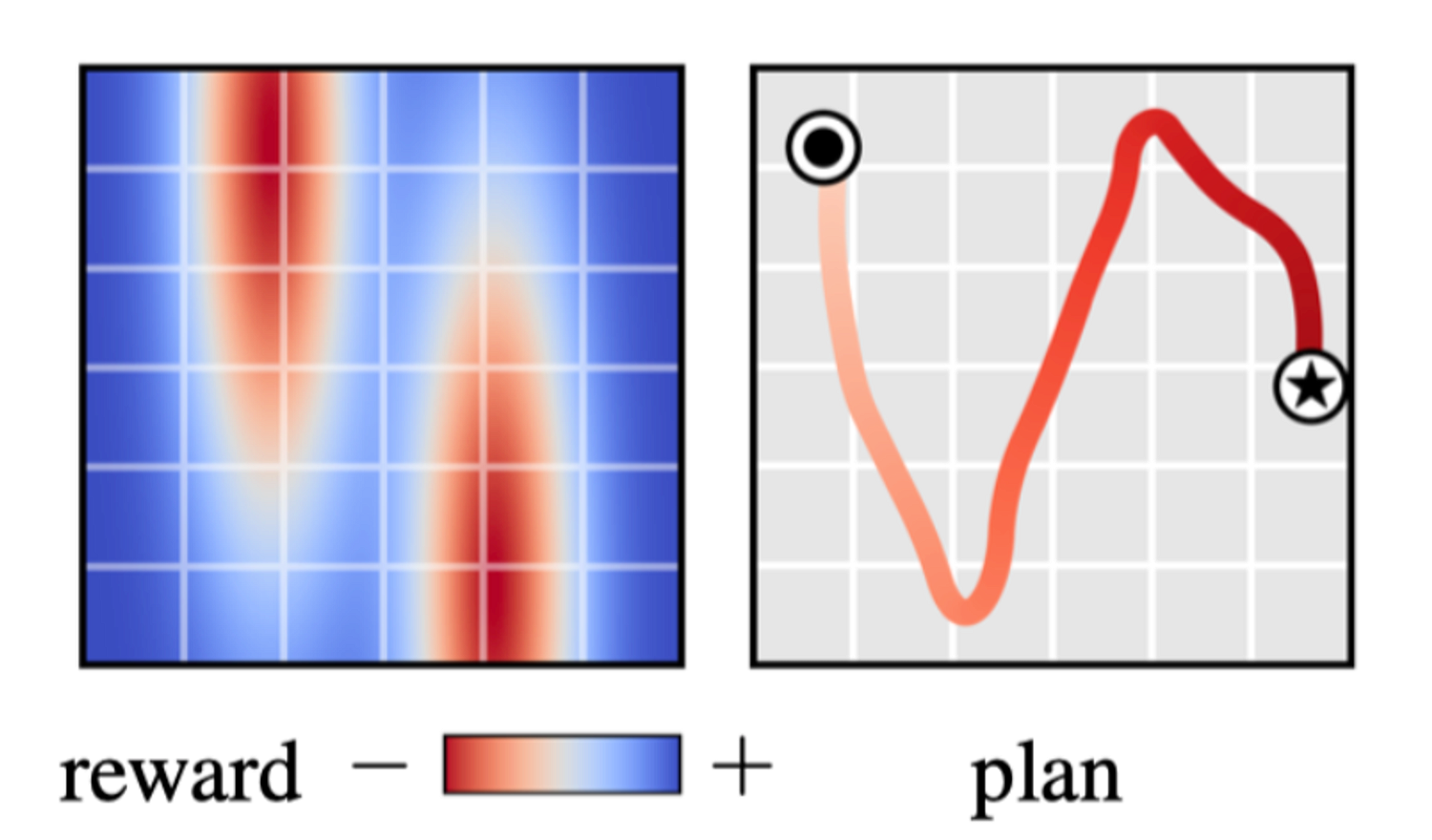
- Learned guidance function: This approach is more common in training image generation models, which involves training a classifier to obtain the guidance function. However, this method requires training a classifier in an adversarial manner, which might lead to unstable training.

Classifier-Free Method
By performing the following transformation, we can obtain the guidance function without training a classifier. The two terms below are known as the unconditional score and the conditional score, respectively. In practice, we can omit the input of the conditional score to achieve the unconditional score.

Inpainting
If the control problem involves specific state constraints (such as the initial/target state or constraints), we can simply fix the state and fill in the missing parts of the distribution. This approach is extremely useful in goal-reaching and navigation tasks.

📚 Literatures: Research Progress in Diffusion Models for Control and Planning
A detailed summary of each method can be found here.
The heart of the diffusion model is understanding how to obtain the score function. Based on the methods for obtaining the score function, what to diffuse, and how to impose constraints/objectives, we can categorize the recent research in diffusion models for control and planning into the following three axes:
Axis 1: How to Get the Score Function
- Data-driven: Learning from data by manually adding noise
- Hybrid: Learning from another optimization process
- Model-based: Calculating analytically from the model
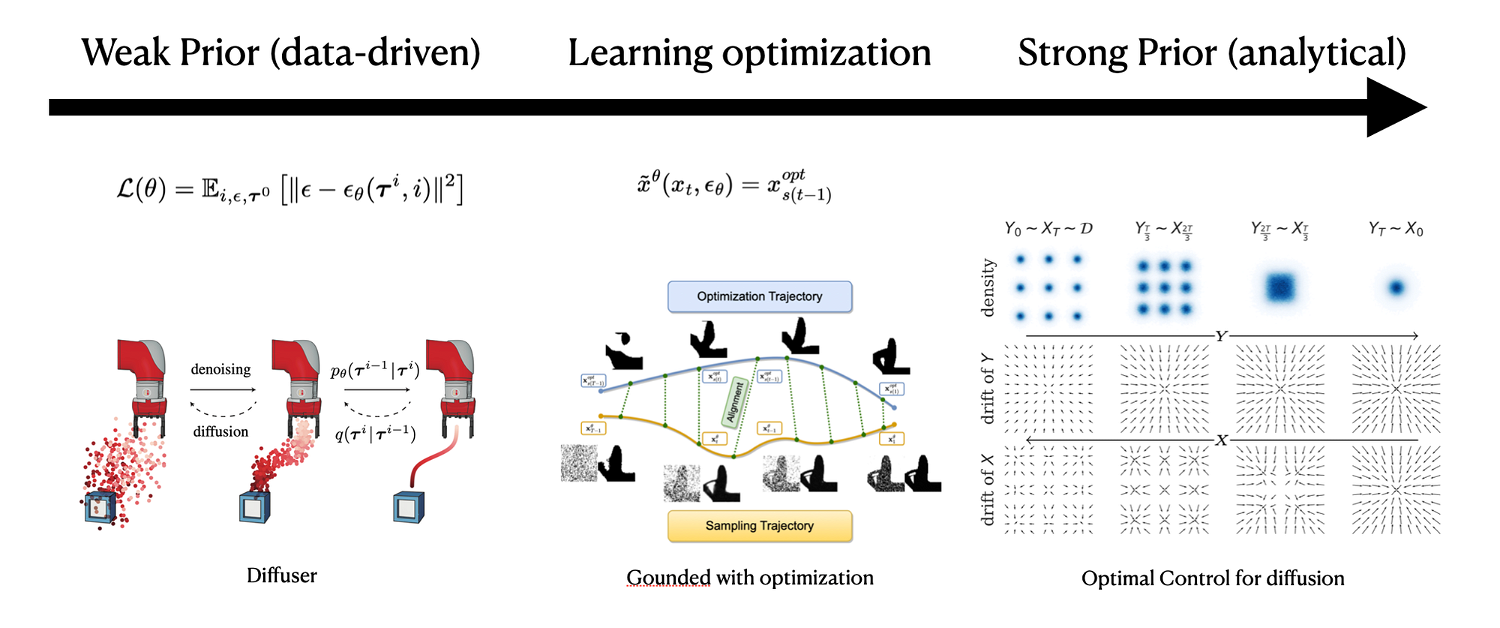
The data-driven method is the most common approach to obtaining the score function, which involves adding noise to the data and then training the model to predict the score function. The hybrid method learns the score function from the intermediate results of another optimization process, typically used in specific optimization problems. Finally, if you can calculate the score function analytically, then you can use Langevin dynamics to estimate the final distribution.
Axis 2: What to Diffuse
- Action: Directly diffuse for the next action
- State: Learn the model
- State-sequence: Diffuse for the next state sequence, or sometimes state-action sequence, or action sequence (for position control)
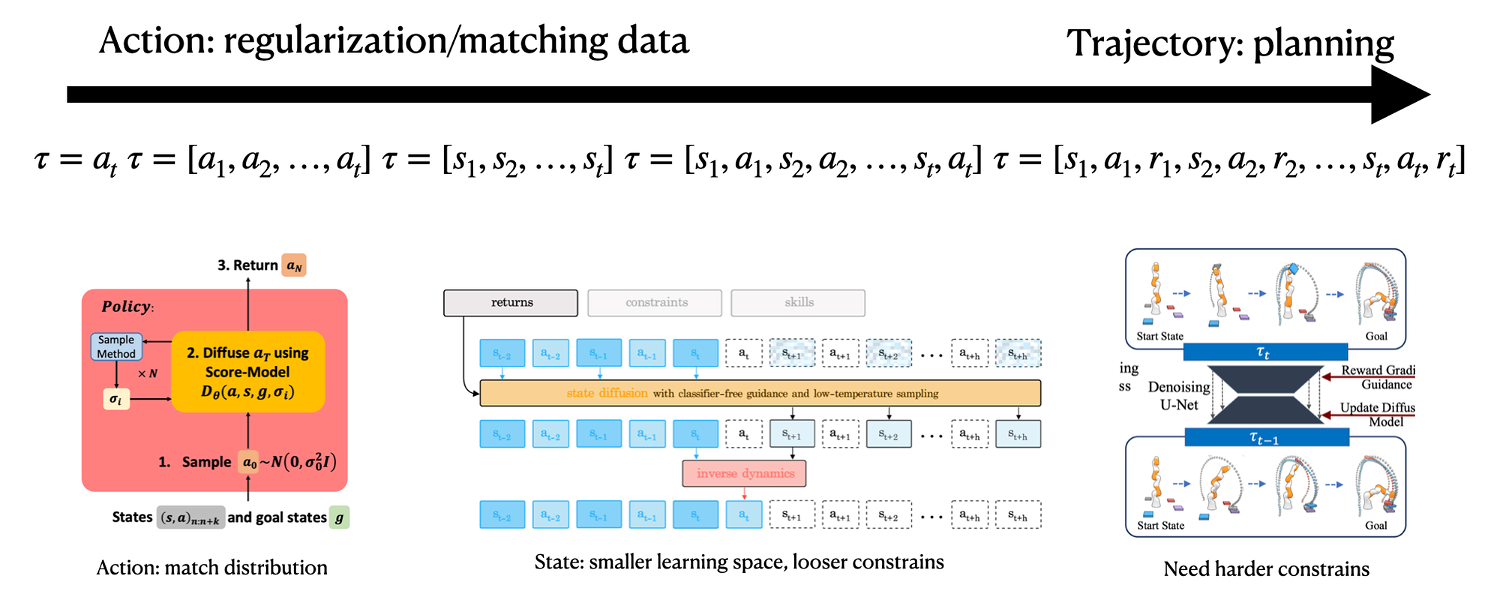
What to diffuse depends on the goals. For instance, to regularize the action distribution to the dataset, diffusing the action is suitable. To learn a dynamically feasible optimal trajectory, diffusing the state-sequence is appropriate. Sometimes, diffusing the action sequence makes execution easier, while other times inverse dynamics are needed to obtain the action sequence.
Axis 3: How to Impose Constraints/Objectives
- Guidance function: Predefined or learned
- Classifier-free: Use the unconditional score and conditional score
- Inpainting: Fix the state and fill in the missing parts of the distribution

The guidance function is the easiest way to impose constraints/objectives, which involves multiplying the guidance function with the model's distribution. The classifier-free method uses the unconditional and conditional scores to impose constraints/objectives, as seen in methods like
decision diffuser, adaptive diffuser, etc. Inpainting involves fixing the state and filling in the missing parts of the distribution, useful in goal-reaching or navigation tasks. This approach is complementary to the guidance function and classifier-free method.One interesting work in this line called
safe diffuser is to solve the quadratic programming (QP) problem at each step to add hard constraints. This method is useful in safety-critical tasks, where they prove that the diffusion model can satisfy the constraints if it converges.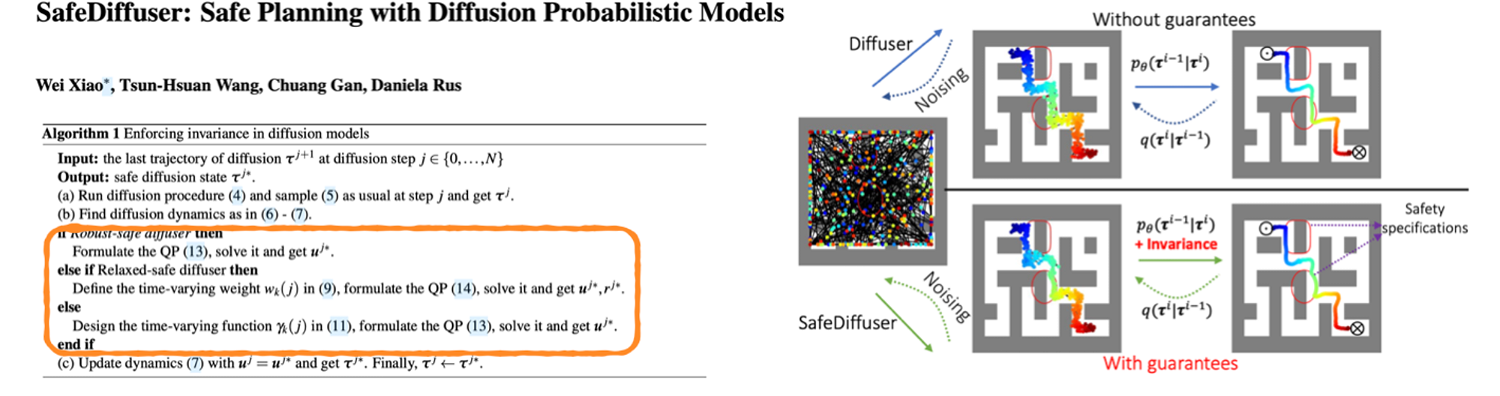
📝 Summary & Limitations: What are the Challenges?
From the above discussion, we can see that the diffusion model can be used in control and planning to match the distribution of the dataset, which is widely used in imitation learning, offline reinforcement learning, and model-based reinforcement learning. The diffusion model can be used to learn the policy, the planner, or the model, which can also be viewed as a distribution matching problem.
Why Does Diffusion Work?
Compared with learning the explicit policy directly or learning the energy-based model, the diffusion model can handle multimodal distribution and higher-dimensional distribution matching by iteratively predicting the score function. This greatly smooths the distribution matching process and makes the training more stable and scalable.
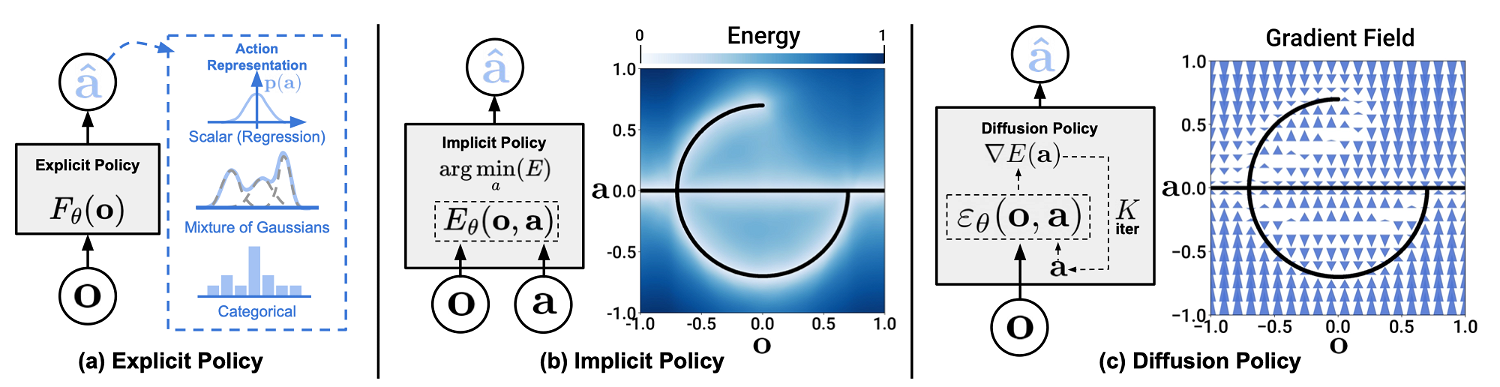
Limitations
However, the diffusion model also has its limitations, which include:
- Computational cost: The diffusion model requires a longer time to train (a few GPU days compared with tens of minutes) and inference (iterative sample steps compared with one forward pass). This makes high-frequency control and planning difficult to use with the diffusion model.
- Handling shifting distribution: In online RL, the distribution of the policy will keep changing. Adapting the diffusion model to the new distribution requires a large amount of data and a long time to train. This limits the diffusion model to be trained in a fixed rather than a dynamic dataset.
- High variance: Depending on the initial guess and random sampling, the variance of the diffusion model is high, which limits its application in high-precision or safety-critical tasks.
- Constraint satisfaction: The diffusion model does not guarantee to satisfy the constraints, especially when tested in a constraint different from the training set. This limits its application in adapting to new constraints and tasks.
Resources
For more information, please refer to the following resources:
Paper list with labels: A detailed summary of recent papers organized by me.
Diffusion for RL survey paper: A comprehensive survey paper on diffusion models in RL.
Diffusion for RL repo: A comprehensive repo on diffusion models in RL.
Awesome Diffusion RL repo: Another comprehensive repo on diffusion models in RL.