CoVO-MPC deployed to Crazyflie trajectory long exposure photo.
Abstract
Sampling-based Model Predictive Control (MPC) has been a practical and effective approach in many domains, especially in model-based reinforcement learning, thanks to its flexibility and parallelizability. Despite its appealing empirical performance, the theoretical understanding, particularly in terms of convergence analysis and hyperparameter tuning, remains absent.
In this paper, we precisely characterize the convergence property of a widely used sampling-based MPC method, Model Predictive Path Integral Control (MPPI). We show that MPPI enjoys at least linear convergence rates when the optimization problem is quadratic. We then extend to three non-quadratic settings, including general systems. Our theoretical analysis directly leads to a novel sampling-based MPC algorithm, CoVariance-Optimal MPC (CoVO-MPC) that optimally schedules the sampling covariance. Empirically, CoVO-MPC significantly outperforms standard MPPI by 43-54% from simulations to real-world quadrotor agile control tasks.
Motivation: the popular sampling-based MPC algorithms lacks of theoretical understanding
Sampling-based MPC becomes prevalent in motion control and model-based RL for its flexibility and parallizability.
The following figure shows different sampling strategy of CoVO-MPC and MPPI controlling a 2d drone. Both algorithm do a receding-horizon control by sampling trajectories (the green area) at each time step.
However, there is no convergence analysis to it, which leads to tune hyperparameters heuristically. For instance, MPPI use dynamic-agnostic isotropic Gaussian to sample trajectories, which leads to sub-optimal performance.
MPPI: sampling with isotropic Gaussian, cannot track the trajectory very well.
CoVO-MPC: sampling with optimized covariance matrix, better tracking performance.
Contribution: first convergence analysis and optimal covariance design algorithm
We first proves MPPI’s convergence and provide insights into optimal sampling covariance design. CoVO-MPC is proposed to optimize sampling covariance according to the optimization landscape.
CoVO-MPC achieve better performance by using a optimized sampling covariance matrix based on our theory.
Performance: CoVO-MPC demonstrate better performance in both sim and real
Performance
We evaluated our algorithm in three environment:
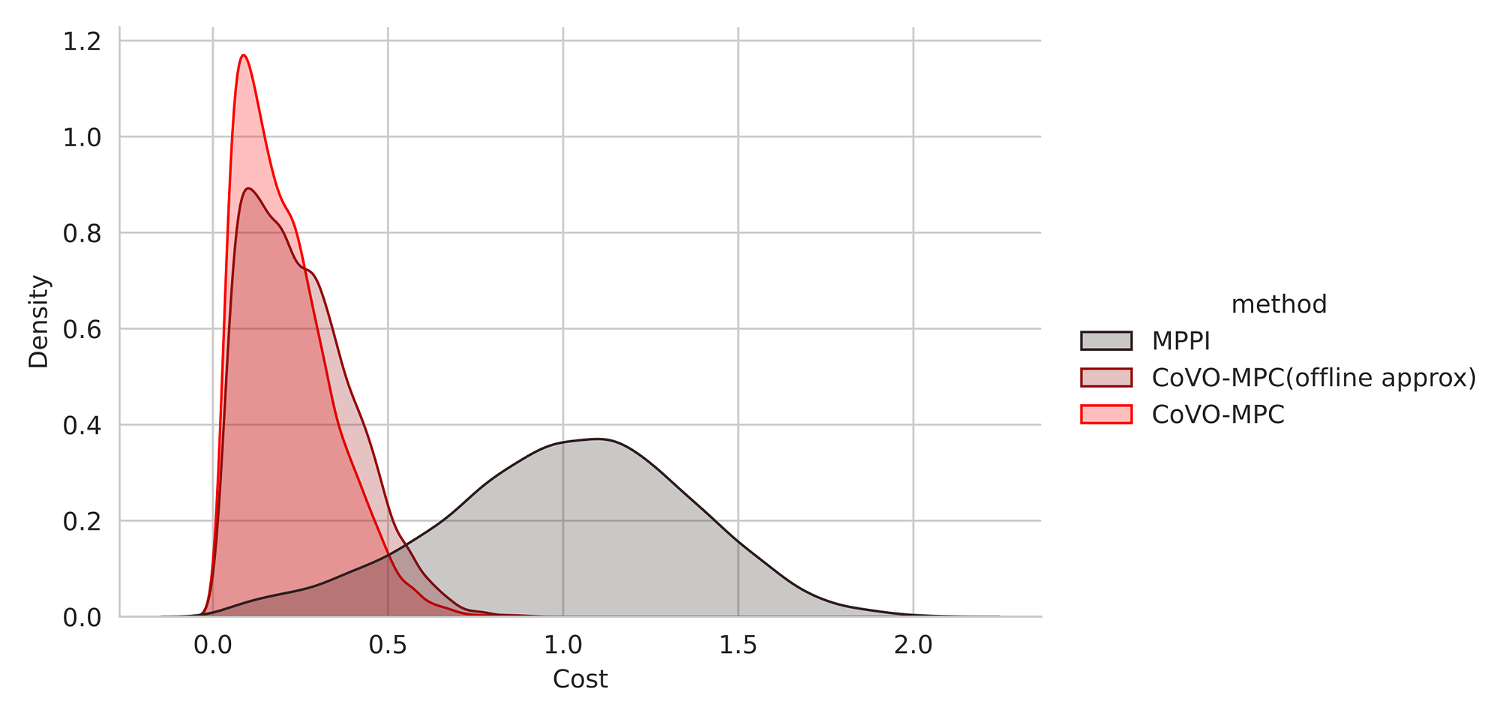
The evaluated cost of CoVO-MPC is 43-54% lower than MPPI.
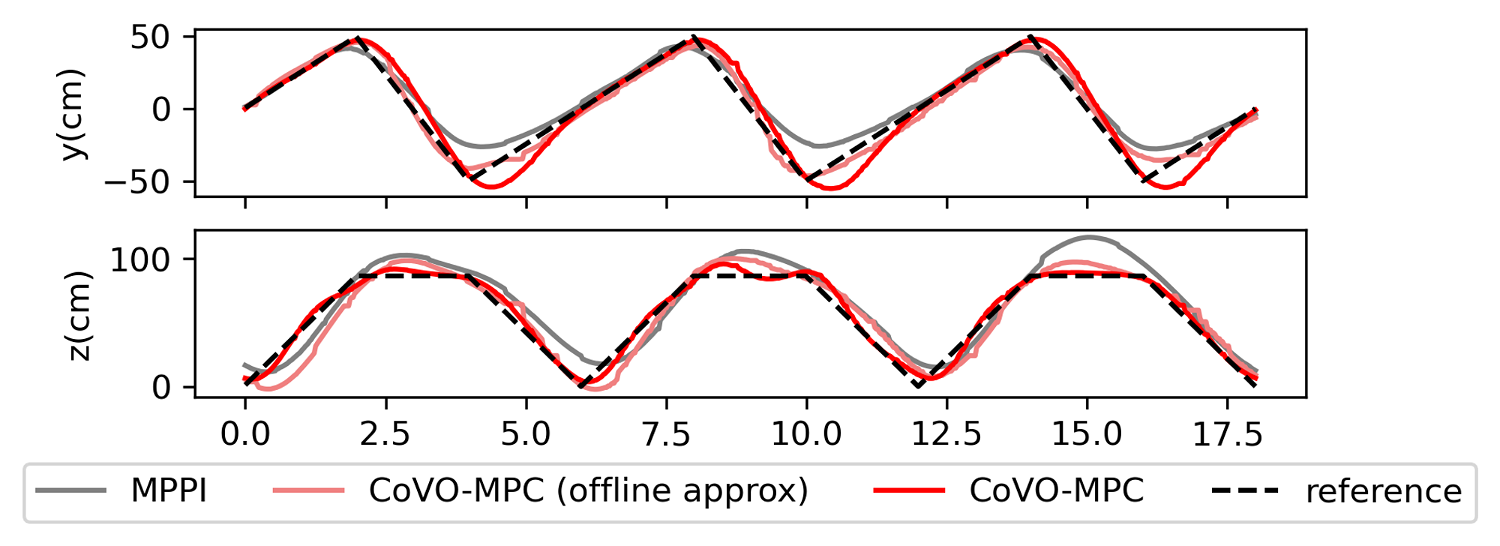
CoVO’s Performance compared with MPPI. Our offline approximation variant achieve better performance with the same computational cost as MPPI.
Real-world experiment
Real-world trajectory get from zig-zag tracking task.
How it works: CoVO-MPC samples lower-cost trajectory by a optimized covariance matrix
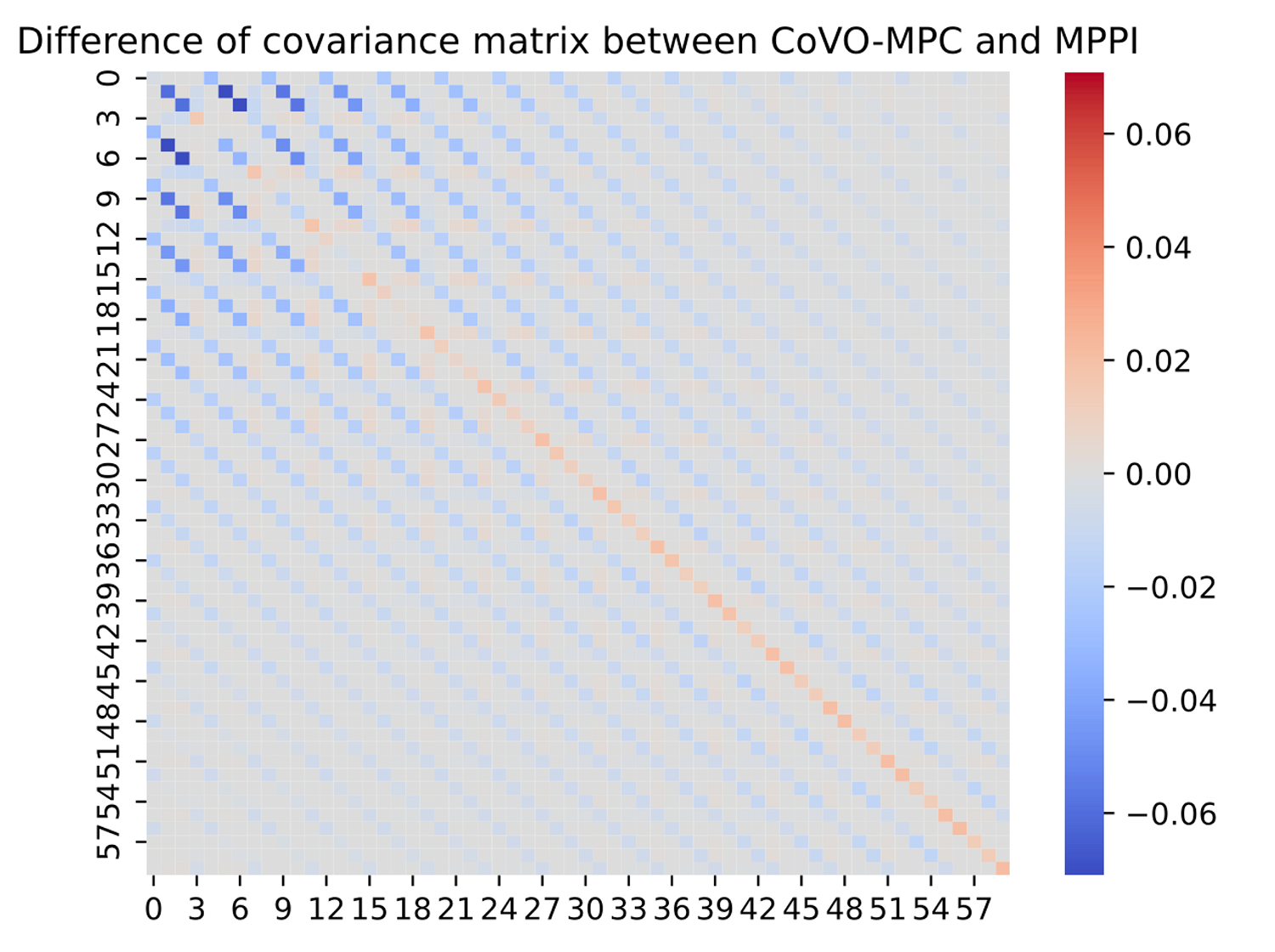
CoVO-MPC optimized the sampling covariance matrix to sample better trajectories, which contribute to higher sample efficiency and performance.
Difference between covariance matrix optimized by CoVO v.s. MPPI
Our sampling strategy generate to lower-cost trajectories.
Citation
@misc{yi2024covompc,
title={CoVO-MPC: Theoretical Analysis of Sampling-based MPC and Optimal Covariance Design},
author={Zeji Yi and Chaoyi Pan and Guanqi He and Guannan Qu and Guanya Shi},
year={2024},
eprint={2401.07369},
archivePrefix={arXiv},
primaryClass={cs.LG}
}